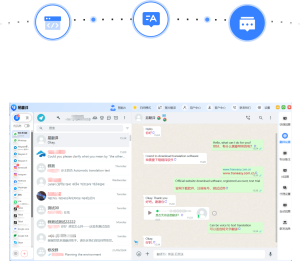
要在易翻译中实现拍照识别马格里布阿拉伯语,先进入“拍照取词”或“图像翻译”功能,授权相机与存储权限,选择识别语言为阿拉伯语或马格里布方言(若有),调整光线和对焦后拍照或导入图片,裁切含文本区域并确认识别引擎与目标语言,如无方言选项可用阿拉伯语或自动识别,识别后可编辑校对并保存或导出,并可保存导出为文本.

先说清楚:什么是马格里布阿拉伯语,为什么识别有难度
先把概念弄明白,才好知道下一步怎么调设置。*马格里布阿拉伯语*(Maghrebi Arabic)指的是北非沿地中海一带的方言群体,代表性地区包括摩洛哥、阿尔及利亚、突尼斯和利比亚等。它在口语上与标准阿拉伯语(MSA)差别明显,有独特词汇、发音和句法。书写上通常使用阿拉伯字母,但会夹杂非标准拼写、拉丁字母(即“Arabizi”)或本地方言词汇。
这些特点导致两层挑战:一是OCR(光学字符识别)遇到方言拼写或非标准字体时会出错;二是即便字符被正确识别,翻译模型把口语方言转成汉语时也可能丢上下文或误译。所以在易翻译里想做“拍照→识别→翻译”的链条,就要同时处理拍照质量、识别语言选择和翻译后校对。
准备工作:在动手前把这些基础准备好
- 更新App:确保易翻译是最新版,很多语言包或OCR引擎的改进都通过更新发布。
- 权限设置:相机、麦克风、存储(文件访问)权限需允许,否则无法拍照、导入或保存识别结果。
- 联网状态:有些OCR或翻译引擎云端识别更准确,建议在网络良好时使用;若使用离线包,请确认已下载阿拉伯语语言包和相关模型。
- 样本准备:如果要批量识别,先准备几张代表性样张测试不同光线、字体和方言词汇。
在易翻译中设置拍照识别马格里布阿拉伯语:逐步操作(通用流程)
不同版本的易翻译界面细节会有差别,下面按常见逻辑给出一步步可执行的流程,遇到界面不同的地方,我也会说明替代操作。
- 打开拍照功能
- 启动易翻译,主界面选择“拍照取词”或“图像翻译”模块(如果看到“拍照”“取词”“图像识别”等类似字样,均为同类功能)。
- 授权并检查摄像头
- 首次使用会弹出权限请求,选择允许相机和存储访问;设置里也可以手动打开(系统设置→应用→易翻译→权限)。
- 选择识别语言
- 在拍照取词界面找“识别语言”或“源语言”下拉列表,优先查找“马格里布阿拉伯语 / Maghrebi Arabic / 北非方言”等选项。
- 如果界面没有明确的“马格里布”选项,选择“阿拉伯语(自动检测)”或仅选择“阿拉伯语(Arabic)”。多数情况下,OCR先识别文本为阿拉伯字母,翻译阶段再决定方言化处理。
- 选择翻译目标语言
- 将目标语言设置为中文(简体或繁体),或一开始选英语做中间语以便排查识别错误。
- 选择OCR/识别引擎(若可选)
- 一些版本允许在“设置”里选择识别引擎(如本地引擎、百度识别、谷歌识别等)。*如果看到多个引擎选项,优先试用云端大厂的引擎,因为它们在多样字体和噪声下更稳*。
- 拍照或导入图片,并裁切
- 拍照后用应用内裁切工具圈选含文字的区域,去掉多余背景,能显著提升识别率。
- 执行识别并查看结果
- 确认后点“识别”或“翻译”按钮。识别完成后,注意检查原文的字符识别(OCR结果)与翻译文本是否一致。
- 编辑与校对
- 识别到的文字可手动编辑(特别是方言词汇),修改后再点翻译以得到更准确的中文结果。
- 保存、导出或分享
- 识别结果通常支持保存为文本、复制到剪贴板或导出图片/文本文件,按需操作。
如果应用提供“方言识别”开关
部分翻译工具会有“方言识别/地方语支持”的单独开关。如果在易翻译的设置里看到类似选项,打开它可能让系统在翻译阶段考虑方言词汇,提高翻译自然度。但这类功能并非所有版本都有,且方言模型普遍没有标准语模型成熟,因此效果会参差不齐。
若找不到“马格里布方言”选项:三个可行替代策略
- 用“阿拉伯语(自动检测)”+手动校对:先以阿拉伯语识别出文本,再根据常见马格里布词汇手动纠错。
- 选择MSA(标准阿拉伯语),再在翻译结果中纠正方言用词:这适合书面文字或教育材料,口语化文本误差会大。
- 混合方法:OCR识别→英译中作为中间媒介:先把识别文本翻译成英语(如果英语版本在你判断上更易理解),再将英语翻译成中文,这在某些场景能规避直接从方言到中文的模型盲点。
拍照取词的实用技巧(让识别率上升的细节操作)
- 光线:自然散射光最佳,避免强背光或反光。夜间拍摄建议开启补光或移动到光源充足处。
- 角度和平整度:相机与文字面尽量垂直,避免过大的透视畸变;有弯曲的纸张先把纸摊平。
- 分辨率:拍高分辨率照片,文字越清晰,OCR越稳。
- 裁切:只保留文字区域,去掉复杂背景或图案。
- 字体样式:手写或花体识别率低,若是手写建议尝试手动输入或语音识别。
- 多拍几张:不同角度或不同对焦点拍几张,选择最佳识别结果。
识别后如何校验与提高翻译质量
识别到文本后,不要把自动生成的翻译当成最终稿。以下是几步简单可行的校验流程:
- 先看OCR原文:确认每个阿拉伯字是否被正确捕捉,常见误识别包括尾字母、短元音和断字。
- 识别结果改写为标准语再翻译:把方言词换为标准阿拉伯语对应词,再使用翻译功能,往往比直接方言翻译更通顺。
- 利用上下文:方言翻译有强依赖上下文的特性,若是一整段文本,先翻译整段比一句一句更好。
- 请教母语者或对照词典:对于重要文本,最好找懂当地方言的人帮忙校对。
小表格:常见设置与推荐值
| 设置项 | 推荐值 |
| 识别语言 | 马格里布阿拉伯语(若有)或 阿拉伯语(自动检测) |
| OCR引擎 | 云端大厂引擎(Baidu/Google等)优先;无网络时用本地引擎 |
| 目标语言 | 中文(简体)或英语作为中间语 |
| 图像预处理 | 裁切、去噪、增强对比、置平 |
| 后处理 | 手动校对方言词并替换为标准语再翻译 |
常见问题(FAQ)
- Q:识别出来都是乱码或方块字,怎么办?
A:多半是字体或编码问题。先确认拍得清楚、是否存在反光,换个角度重拍;若是图片内含拉丁字母(Arabizi),尝试切换到英语/拉丁识别或手动输入。
- Q:为什么方言翻译总显得不自然?
A:翻译模型对标准阿拉伯语训练数据更多,方言数据少且地域差异大。能做的是把方言词手动替换为标准词,或将识别结果给懂方言的人校对。
- Q:能否离线实现高质量的马格里布方言识别?
A:目前离线模型通常覆盖标准语更好,方言支持有限。若必须离线,先下载完整阿拉伯语语言包并测试不同样本,必要时准备人工校对流程。
进阶技巧:把不同工具组合起来,提高成功率
- 先OCR后多引擎比对:用易翻译做一次OCR,再把识别文本粘到另一个在线翻译或词典里比对译文,取多个结果的共同部分。
- 用语音作补充:如果手边有人能读出原文或口语句子,使用语音识别+实时翻译往往比照片识别更准。
- 建立本地短语表:工作中遇到重复短语或地名,可把常见方言词加入自定义短语库(若易翻译支持),下次识别后自动替换。
- 借助社群或学术资源:有时对某些特别方言词,查阅《马格里布阿拉伯语词典》之类资料,或向语言学社区求助,能解决疑难。
说到这儿,你大概能把易翻译里拍照识别马格里布阿拉伯语的流程完整跑通了。实践中多试几张不同条件下的照片,会比只读说明更有收获——语言本来就是活的,按步骤操作,再结合观察和校对,就能把自动化工具的效果拉得更稳一点儿。就像我以前常常边拍边改,有时会发现某个招数特别灵验,下一次就自然记住了。